Whether the term microservice for you indicates a technology, an architecture, or a buzzword to land you that next dev job, you need to be familiar with the term. You need to know why there is buzz around it, and you need to be able to code and deploy a microservice.
Microservice Successes vs Failures
However, how successful are Microservices? A quick google search does not show promising results. One O’Reilly study found that less than 9% consider their microservices implementation a complete success. Most implementations report partial success at best. Why is this? Could it be that microservices are like any tool; great when used correctly, less than adequate when not. Remember, you can successfully pound a nail with a wrench, but a hammer is better and a nail gun is better than a hammer when coupled with power, a compressor, and enough space to use the tool. If you are building a tool that microservices isn’t suited for and you use microservices anyway because it is a buzzword, you are going to struggle and even if you don’t fail, you won’t have complete success.
Should you implement Microservices?
Should you be looking to implement microservices? Do you have a monolith that could be broken up with microservices?
This really depended on your architecture and what you think you mean when you say microservice. There is a breakdown in the industry in a clear definition of what is a microservice.
Is there a better alternative to a microservice? That answer depends highly on what you are trying to do.
Microservice Architecture Analysis with S.O.L.I.D.
The initial idea of Microservices is based on first of the S.O.L.I.D. principles. When looking at any one microservice, it fulfills the S in solid. But what about the other letters? What about other principles beyond SOLID, such as the Don’t Repeat yourself (DRY) principle or Big O? Do microservices still hold up?
Let’s do an analysis of some of these concepts.
S = Single Responsibility
The S in S.O.L.I.D. literally means Single Responsibility, which is the very premise of a microservice. A microservice should have a single responsibility. A microservice excels at this. Or it is supposed to. Implementation is where things can get dicey. How good is your development team at limiting your microservice to a single responsibly? Did you create a microservice of a micromonolith?
Theoretical Score: 100% – complete success
Implementation Score: 50% to variable – half the developers I interview can’t even tell me what each letter in S.O.L.I.D. stand for, let alone hold their microservice to it.
O = Open Closed Principle
The O in S.O.L.I.D. means Open for extension and closed for modification.
This principle is a problem for microservice architectures. The whole idea of microservices goes against this principle. In fact, Microservices are actually a 100% inverse of the recommendation made by the O in S.O.L.I.D. because microservices are open for modification and closed for extension.
If a microservice needs to be changed, you change it. Those changes automatically deploy.
Theoretical Score: 0% – complete failure
Implementation Score: 0% – complete failure
L = Liskov substitution principle
There terribly non-intuitive name aside, this principle means that if you substitute an parent object with a child, the code shouldn’t know or care that the child was used. You can now add substituting and interface with any concrete implementation and the code should just work regardless.
How do you do inheritance with a microservice? How do you substitute a microservice? You could create a child microservice that calls a microservice, but inheritance is just not a microservices concept.
Theoretical Score: N/A or 0% – complete failure
Implementation Score: N/A or 0% – complete failure
I = Interfaces Segregation principle
The I stands for Interfaces Segregation, which means you should have the minimal possible defined in any one interface. If more is needed, you should have multiple interfaces. A single microservice excels here as another principle idea of a microservice is that it has a defined interface for calling it and that it is a small (or micro) of an interface as possible. However, what if you need a slight change to an interface? Do you:
- Edit your microservice’s interface?
You risk breaking existing users.
- Add a second interface?
Doing this increases the size of your microservice. Is it still a microservice? Is it slowly becoming a mini-monolith now?
- Version your microservice interface in a new version, but keep the old version?
This quickly can become a maintenance nightmare.
- Or create a completely separate microservice?
Wow, creating a whole other microservice for one minor change seems like overkill.
Theoretical Score: 100% – complete failure
Implementation Score: 50% to variable – there is no clearly defined path here, you have to trust your developers do make the right decision.
D = Dependency Inversion
D means dependency inversion, which means you should depend upon abstracts and not concretes. Well, how do you do this if you are a microservice? What about when one microservice depends and three other microservices? And those other microservices are REST Apis? How do you depend on them abstractly?
This is a nightmare. The most difficult part of coding is depending upon external systems, their uptime.
Many developers and architecture will simply say that this is easy, just use queuing, messaging, a bus, but don’t make synchronous calls. If the system is down, it is down, regardless of whether it is synchronous or not. With synchronous calls, the caller can at least find out if a system is down immediately whereas with event-driven bus systems, this can be difficult to know. If one microservice is down, preventing a UI from displaying for a user, do you think a user cares whether you are synchronous or asynchronous? No. They care about clear messaging, which is harder to do asynchronously.
The efforts to solve this microservice conundrum often lead to an architecture that is far more difficult to maintain than the monolith. Remember, just because something is a monolith, doesn’t mean it was poorly architected.
Theoretical Score: 25% – extremely low success rate
Implementation Score: 25% to variable – there is no clear best practice here.
Other Tried and True Principles
Don’t Repeat Yourself (D.R.Y.)
Microservices don’t even try with this one. Even the top architects balk at the importance of this with microservices. Almost invariable, they recommend that you DO repeat yourself. With the packaging abilities of this day and age (Maven, NuGet, npm, etc.) there is no excuse for this. Duplicating code is rarely a good idea.
There are exceptions to D.R.Y. For example, Unit Tests. I duplicate code all the time because a self-contained test is better than a hundred tests using the same setup code. If I need to change the setup, I risk breaking all the tests using that setup, whereas if I copy my setup, then each test better stands alone and can better isolate what it is trying to test.
Do Microservices fall into the same bucket as Unit Tests? Unit Tests usually find bugs, but don’t usually have bugs themselves the same way production code does. Microservices aren’t like Unit Tests at all as they are production code. If you copy code to 10 production microservices and find a bug, fixing it in all ten places is going to be a problem.
Theoretical Score: 0% – extremely low success rate
Implementation Score: 25% to variable – there is no clear best practice here. An implementor could balance how much code is copied vs contained in packaging systems.
Big O
Microservices can crash and burn when it comes to Big O. Remember, Big O is how many times an action has to be done for a given thing or set of things, N, where N is a variable representing the number of things. If there are two sets of things, you can use multiple variables N, M. And for three sets, N, M, K (see the pattern, just keep adding a variable for each set of things). The action per set of things is often processor or memory or disk space, but it is not limited to those. It can be anything: IP Addresses, docker images, pipelines, coding time, test time.
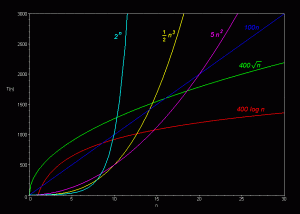
Big O (1) is the ultimate goal. If you can’t reach it, the next best is Big O (Log n). If you can’t reach that, then you are at least Big O (N), which isn’t good. That means that your technology does NOT scale. Worse, you could be Big O(N * M) or Big O (N^2), in which case your technology slows down exponentially and scaling is impossible without a change.
What is the Big O for N microservices in regards to source control? Big O (N)
What is the Big O for N microservices in regards to CI/CD pipelines: Big O (N).
What is the Big O for N microservices in regards to docker containers? Big O (N)
What is the Big O for the number of terraform files (or whatever config you use for your deployment to your cloud environment of choice) for N microservices that you have to maintain? Big O (N)
What is the Big O for N microservices in regards to IP Addresses? Big O (N) – however, you can get to Big O (1) if you configure a intermediary routing service, but now all you’ve done is create a Big O (N) configuration requirement.
What is the Big O for microservices in regards to coding time? Big O (N) – remember, the recommendation from even the leading experts is to ignore the DRY principle and repeated your code.
What is the Big O for a mesh of microservices that have to communicate to each other? Big O (N^2)
A couple of places microservices shine in Big O are:
- Globally shared services. Example: How many NTP services does the world really need? Only one. Which is Big O (1).
- Microservice Hosts (Kubertnetes, AWS, Azure, etc) – these can provide logging, application insights, authentication and authorization for N microservices with a single solution, Big O (1).
The Big O of microservices is terrible and nobody is talking about it. Why have microservices gotten away with being Big O (N) for all this time? There are a couple of reasons:
- Automation has outweighed those concerns.
- Early adoption means few microservices, so Big O is not always a concern when there are only a few of something.
Get past early adoption and start having a lot of microservices, and you will find you are in just as much of spaghetti hell as you were in with your spaghetti code monolith, only now it is harder to fix issues because they span multiple teams, across multiple environments. Wouldn’t it be great it if all those microservices were in 1 place? It was, before you strangled it away into microservices.
So when should you use Microservices?
Well, if you consider a Microservice to be a cloud RESTful service, for cloud-delivered solutions, then microservices are probably going to have a higher success rate for you.
If you are installing on Desktop/Laptops/Mobile Devices, then microservices, as they are defined, are not the best solution. However, that doesn’t mean you should have a spaghetti code monolith. No, if you are installing an application (not just a link to a cloud website) then please, keep your monolith, only instead of breaking it up into microservices on docker containers, look to follow S.O.L.I.D. principals, break it up.
Theoretical Score: 15% – unless we are talking about a global service, where, in those small instances, they are 100%.
Implementation Score: 10% to variable – An implementor could use shared CI/CD pipelines, terraform files with variables (but most are that mature yet). Some might use only 1 public IP, but they still need N private IPs.
The future is bright. As many of these Big O issues are solved, which will come with maturity, microservices will naturally become more attractive.
What microservices are good for?
Single-responsibility shared services
A Network Time Protocol service is a great example of one that should be a microservice. It has one responsibility and one responsibility only. We could have 1 instance of it for the whole world (notice that suddenly made this Microservice Big O (1), didn’t it?). However, distance is a problem, so the United States needs its own, Europe needs its own, and China needs its own. It doesn’t have to be separate code, just the same code deployed to multiple cloud regions.
Many services for cloud products can be single-responsibility shared services, which is why microservices target cloud products so well.
Elasticity
The ability to have a microservice auto-deploy additional instances of it, often in different regions, to support scaling.
What are Microservices NOT good for?
Services that every customer needs their own instance of
Not all services are shared. Some services need to be custom per customer. Microservices are not good for these. Especially if it is a pack of services.
On-Premise software
Microservices are best designed for cloud solutions or internal only integration services. If you sell software that a customer should install on-premise (on-premise means on one of their systems in their environments), microservices are not a good option.
Everything could be in the cloud but not everything should be in the cloud.
- Desktop Applications and Suites such as Microsoft Office, Adobe Creative Suite. Sure there are cloud versions of these, but desktop apps work best as stand-alone desktop apps. That doesn’t mean they can’t integrate with a microservice, but they shouldn’t require a microservice to function (many apps still need to work without internet).
- Networking and other security software: VPN software, desktop management software, or large applications that for many reasons shouldn’t be in the cloud.
You don’t want customers to have to deploy 100 docker containers to install your software on-premise. You just don’t. That doesn’t mean you couldn’t have a single cohesive system that includes microservices all installed on the same server, but the point is, those microservices are by many definitions not microservices if they are on the same server. Instead, they become a cohesive but decoupled single system.
Dark Network Environments
The definition of Dark Network means no access to the internet. That doesn’t mean these environments could have their own internal clouds, with microservices, but chances are, if they don’t have internet access, they won’t need to be accessed by a billion people and need to be elastic.
UI experiences
Like it or not, microservices architecture can degrade the UI experience. Why? Because microservices are usually asynchronous and event-driven. Microservices, especially asynchronous event-driven ones, often make the UI harder to code because you have to call service but you get no response. You then have to code the UI to go obtain the response from an event. This also increases debugging time. Some people say a synchronous microservice is not a microservice. If that is true, then all microservices make the UI harder to code and debug. If microservices make UI code harder, that is a significant con that every implementor should be aware of.
No matter who makes the claim that microservices are 100% decoupled, they are wrong if a UI requires that microservice. If Service X is required by a UI, the UI is coupled to it being up. It doesn’t matter if it is a microservice that fails gracefully or a monolith that crashes without grace. If a customer is in the UI and they can’t do something because a service is down, that service is a dependency, and the belief that changing a UI’s dependency to a microservice solves this is just false. If the UI doesn’t work, it doesn’t work. Just because the code itself isn’t coupled doesn’t mean a UI’s functionality isn’t tightly coupled to a dependent microservice’s existence and uptime.
Options beyond Microservices
Microservices are here to stay and are a great tool for the right uses. But they are not a swiss-army knife. They are best for delivering cloud solutions or taking processing off the client in desktop/mobile apps.
What are some alternatives to Microservices?
- A cohesive but decoupled single system may still be the right solution
Note: What is the difference between a monolith and a ‘cohesive but decoupled single system’? Answer: the lack of tight coupling. A single system without tight coupling is not a monolith. If your system is tightly coupled, it is a monolith. If it is not tightly coupled, it is a ‘cohesive but decoupled single system’.
- A well-architected system that is highly decoupled is not a problem.
- Don’t fix it if it isn’t a problem.
- Don’t fix it just because microservices bigots name-call it a monolith instead of the ‘cohesive but decoupled single system’ that it is.
Note: Some cloud enthusiasts use monolith as a bad word. It isn’t. Some can be prejudiced by their cloud enthusiasm, but you should know that older developers are just as prejudiced by their monoliths, well-architected or not.
- If an existing monolith is poorly architected, you may want to simply update the architecture to be a single cohesive but decoupled system instead of scrapping it entirely for microservices. The strangler pattern can work just as well to create a cohesive but decoupled single system as it does for creating microservices. You might even use single responsibility services (I didn’t say microservice because by some definition they aren’t microservices if they share a system) in your cohesive but decoupled single system.
- Multiple shared cohesive systems,
- Perhaps you can split your system into 50 microservices, or you can have 3 cohesive systems housing 15-20 services (which could be microservices that share a system) each.
- Plugin-based system design – You don’t have to be a microservice to get the benefits of decoupled and microcode.
The strangler pattern works just as well for moving your code to decoupled microplugins as it does for microservices.
How is this different from a cohesive but decoupled single system? It uses plugins whereas a cohesive but decoupled single system doesn’t have to use plugins.
Note: This is my favorite solution. 99% of the benefits of microservices, 100% SOLID, and far fewer drawbacks.
Your code should have a Single Responsibility and vice-versa a single responsibility should have a single set of code (If you have three pieces of code that all have a single responsibility but they all have the same single responsibility, you are not S.O.L.I.D.). Look at interfaces, dependency injection, and please look at plugins. Plugin-based technology gives you almost everything you get for microservices.
Conclusion
Microservices can be a great tool or the wrong tool. Chose to use it wisely.
Note: This is obviously a highly summarized blog article, so please feel free to share your opinion and nit-pick as that is a form of crowdsourcing and is how blog articles get better.