Sometimes, when coding a web application in visual studio, you may want to have the project start in an InPrivate or Incognito window. Browsers, such as Chrome, Edge, Firefox, and others, have a special way to open them that is clean as in no cookies or history or logins and it isn’t tied to your normal browser session. This is called Private browsing. They each brand it a little differently, with Edge being InPrivate and Chrome using Incognito, but they are all private browsing.
Visual Studio can easily be configured to open the browser in private browsing.
Configure Visual Studio to Launch the Browser in Private Mode
Open Visual Studio
Locate your Asp.Net Application and open it
or
Create a new Asp.Net Project (you can throw away this project afterward)
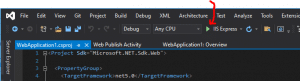
Once the project is open, locate the Debug Target icon, which is a green triangle that looks like a start icon:
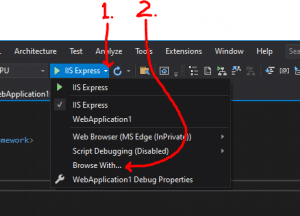
Click the drop-down arrow just to the right of it.
Select Browse with:
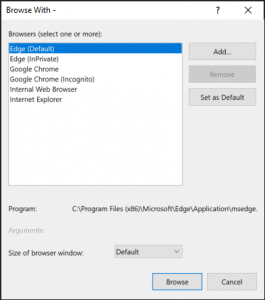
In the Browse With screen, click Add.
Enter one or more of these values: (I entered both)
Now you can change the default if you desire.
My default was set to Edge.
To change the default, highlight the desired browser setting and click Set as Default button.
Click Browse and your app will start in debugging and browse to the local url with your configured default browser.
If you haven’t paid attention to the development world, you might have missed the current movement called “Reuseable Building Block development.” You know, as a kid, we could get blocks are build anything with them. We only had to stack them. Well, having a n-tier stack is very common, now, so stacking isn’t the issue. It is having blocks that are easy to stack. Some are calling it the open source movement, and while most reusable building blocks are open source, not all of them are. Many of the building blocks don’t have to be open source, but can simply be well-documented and work well.
With NuGet and Npm, building blocks are being created and published daily. The problem now is helping other developers recognize this movement. Changing our mindset from, “we can’t use if it wasn’t invented here,” to something more like, “this is our unique stack of building blocks for a unique problem and this stack was invented here.”
I have created a bunch of building blocks for C#. Check out my github account at https://github.com/rhyous. You will see a few reusable building blocks:
Rhyous.Collections – You know all those pesky extension methods your write for collections that are missing from the collections or from linq. I have a lot of them in here.
Rhyous.EasyCsv – A simple tool for working with csv files.
Rhyous.EasyXml – A simpel tool for working with Xml. (You might ask why I don’t have one for JSON, and that is because Newtonsoft.Json and fast.jsona already exist , so another one isn’t needed.)
Rhyous.EntityAnywhere – Wow, have a full rest api and only have to create the model class. Are you kidding, this is probably the coolest project for Web Service APIs since the REST pattern was introduced.Rhyous.SimplePluginLoader – Easily load plugins in your app.
Rhyous.SimpleArgs – Writing a tool with command line arguments? This tool allows you to configure your arguments in a model class and be done. It will output usage and force required parameters and allow for events when a parameter is set, etc.
Rhyous.StringLibrary – You know all those pesky extension methods you write for string manipulations missing from .NET Framework. They are in this library, along with a pluralization tool. Every heard of the The oft forgotten Middle Trim, well, it is in this library, too.
WPFSharp.Globalizer – The best localization library for WPF that exists, allowing you to change language and style (including left to right flow for certain languages) at runtime.
I actually have many more building blocks. Take a look.
I wrote and extension method to DateTime today. I want to call something simple to see if one date is within a two days of another date. There isn’t a within method. I set out to create one and this what I came up with.
The Tiobe index is really missing one piece of information about .Net for its users. Java is #1. So users should use Java, right? Well, maybe not. Let’s talk about the problems with it before we move on.
I am going to make an argument that:
Java is actually a more clear #1 than suggested.
.Net is #2 behind Java, but not as far behind as the Tiobe index makes it appear.
Problem 1 – DotNet Framework is not listed as one a language
.Net has more languages writing against it than just one. That makes it appear less popular because the language is more fragmented. In fact, two of them are in the top 5 or 6. However, the fact that a dll compiled in either language can be consumed by either language is really not described here. I am not saying this should be on the same list of programming languages, but Tiobe should make it clear that the combined .Net languages show .Net as being used more heavily. Similary for Java, there are other languages that compile to the JVM. Perhaps there should be a page on compile target: What percent of languages compile to .Net’s Common Intermediary Language or compile to the Java Virtual Machine or to machine code or don’t compile at all?
As for intermediary languages, there are only two that stand out: Java and .Net. And Java is #1 but it only has 1 in the top 10. .Net has two in the top 10 and the combined languages are easily a rival to the combined JVM languages.
Look at the Tiobe index and add up the .Net Framework languages:
.Net Framework Languages
Language
2019 Tiobe Rating
Visual Basic .Net
5.795%
C#
3.515%
F#
0.206%
Total
9.516%
Notice that combined, the number of the three main .Net languages is %9.516. That puts .Net in the #3 position behind Java, C, and C++.
Problem 2 – Some .Net languages are missing and may be lumped in other languages
What about Visual C++? Yes, you can write .Net code in C++. However, that language is completely missing from Tiobe. Or is it? Is all Visual C++ searches lumped in with C++? If so, shouldn’t Visual C++ be separate out from C++. What is the Tiobe raiting Visual C++ would get? That would be hard to guess. But it is a language has been around for almost two decades. Let’s assume that a certain percentage of C++ developers are actually doing Visual C++. Let’s say it is more than F# but quite a lot less than C#. Let’s just guess because unlike Tiobe, I don’t have have this data. Let’ say it was .750. Again, this is a wild guess. Perhaps Tiobe could comment on this, perhaps they couldn’t find data on it themselves.
.Net Framework Languages
Language
2019 Tiobe Rating
Visual Basic .Net
5.795%
C#
3.515%
F#
0.206%
F#
0.206%
Total
10.266%
As you see, .Net combined is clearly #3 just by combining the .Net languages. Well past Python, which in fact can be used to both code for .Net (IronPython) and for the Java JVM (Jython). What percent of python is used for that?
Here is a wikipedia list of .Net-based languages: https://en.wikipedia.org/wiki/List_of_CLI_languages.
Similarly, for Java, languages like Groovy up it’s score. Here is a wikipedia list of Jvm-based languages: https://en.wikipedia.org/wiki/List_of_JVM_languages.
Problem 3 – Visual Studio is Awesome
For all the problems and complaints of bloat, Visual Studio is the move feature rich IDE by such a long ways that I doubt any other IDE will ever catch up to it, except may Visual Studio Code, which, however, is just as much part of the Tiobe index problem as Visual Studio is.
The better the tool, the less web searching is needed. The breadth of the features in Visual Studio is staggering. The snippets, the Intellisense, the ability to browse and view and even decompile existing code means that .Net developers are not browsing the web as often as other languages. My first search always happens in Intellisense in Visual Studio, not on Google. The same features and tooling in other IDEs for other languages just isn’t there. Maybe Exclipse, but only with hundreds for plugins that most developers don’t know about.
After Visual Studio 2012 released, the need to search the web has decreased with every single release of Visual Studio. I am claiming that C#, which is the primary .Net Framework language microsoft code for in Visual Studio, is used far more than Visual Basic .Net. Tiobe has Visual Basic .Net at 5.795% and C# at 3.515%, but reality doesn’t match Tiobe’s statististics. C# is used far more than Visual Basic .Net.
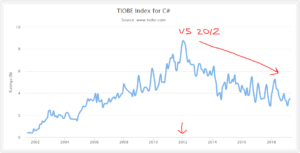
I am making the hypothesis that as the primarily coded language in Visual Studio, C# would appear to go down in the Tiobe index since the release of Visual Studio 2012. Let’s test my hypothesis by looking at the Tiobe year-by-year chart for C#. Do we see the Tiobe index going down starting with the release of VS 2012?
After looking at the Tiobe index, I am upgrading my claim from a hypothesis to a theory.
Other .Net languages may not experience the same as C# as the tooling in .Net is primarily focussed around C#.
So the reality is that the Tiobe index is showing the data it can find from search engines, but the data for C# is just not there because a lot of the number of ways C# deflects the need to search.
I hypothesise that C# reached a peak Tiobe index of 8.763% and it’s usage has not actually gone down. Instead, it has gone up. However, the data doesn’t exist to prove it. Assuming the hypothesis is correct, and C# usage has gone up, then the rate it should be is closer to 9 or 10. That means the C# is probably #3 on it’s own.
If we adjust to take this problem into account, simply by using the 2012 index and not assuming the the usage rate has gone up, we see the following:
.Net Framework Languages
Language
2019 Tiobe Rating
Visual Basic .Net
5.795%
C#
8.7%
F#
0.206%
F#
0.206%
Total
17.606%
Now, I am not saying .Net is above Java with my hypothesized 17.505% adjusted rating. Java has other languages as well that compile to the JVM that would similarly raise it and it is still #1.
Problem 4 – Direct linking to or searching on Microsoft.com
Microsoft has done a great job with a lot of their documentation. Some of this could be attributed to Visual Studio as well. After clicking a link in Visual Studio, we are taking directly to a site like https://msdn.microsft.com where I do a lot of my language searches.
Also, Microsoft has built a community where customers can ask questions and get data.
Tiobe has a nice document that clearly states which search enginers did not qualify and what the reason they didn’t qualify was.
I would argue that a significant amount of searches for .Net languages are done primarily on Microsoft.com. I can only provide personal data. I often go directly to the source documentation on Microsoft.com and search on Microsoft’s site. And once I am there almost all further searches for .Net data occur there.
Microsoft has more C# developers in their company that many programming languages have world wide. Are they doing web searches through the list of qualified search engines?
Problem 5 – Better documentation
I hypothesize that the better the documentation, the less searching on the web is required. I also hypothesize that Microsoft is one of the best at providing documentation for it’s languages.
Because the documentation for .Net framework is so excellent, the question is usually answered in a single search instead of multiple searches that languages that are less well documented may require.
Problem 6 – Education
Colleges are teaching certain languages. Python and C++ are top languages taught in college. I would estimate that because of these, the languages primarily taught in college have far higher good search rates. Unfortunately, .Net languages, because of their former proprietary nature (which is no longer the case with the open source of .Net Core), were shunned by colleges.
It would be interesting to filter out searches by college students. Unfortunately, how would Tiobe know that a search came from a college student or not.
Problem 7 – Limited Verbage
Tiobe is only looking at certain words. The words that are being queried are:
C#: C#, C-Sharp, C Sharp, CSharp, CSharp.NET, C#.NET
Further, Tiobe says:
The ratings are calculated by counting hits of the most popular search engines. The search query that is used is
+"<language> programming"
This problem piggy backs on Problems 3, 4, and 5. Visual Studio is so awesome, that we know exactly what we are looking for. As a C# developer, I don’t type C# into my searches hardly at all. I type something like: WebApi, WCF, WPF, System.Net.Http or Entity Framework or LINQ, Xamarin, and many other seaches. Microsoft documentation is so clear and specific (Problem 5) that we can do highly specific searches without including the word C#.
Yes, other languages have libraries, too, but do other languages have Microsoft’s marketing department that brands libraries with trademarks and logos and makes that brand the goto phrase to search? I don’t think there is a single other programming language other than C# that does this. Microsoft is lowing the web searches for C# by their awesome marketing.
This is further evidence to explain why the actual usage of C# has gone way up while the Tiobe index has gone way down. Asp.Net, Ado.Net, Razor, WCF, WebApi, WPF, WF, etc. What other language has logos and brands around specific parts of a language?
Problem 8 – Is C# always seen as C# in search engines
I don’t always add C# to my google searches. However, when I do, it is somehow changed to just C. The sharp symbol, #, is often removed. This recently stopped happening on Google, but it used to happen with every search in every browser. It was frustrating.
Has this been addressed in search engine stats?
Conclusion
The belief that C# is in the 3% range is an unfortunate error of circumstances. And .Net should be looked at is the second most important tool for a programmer, second only to Java, and above all other programming languages.
Step 1 – Add a method to get the list of files in a local directory
This isn’t the focus of our post, however, in order to upload all files in a directory recursively, we have to be able to list them. We are going to create a method that is 10 lines of code. The method has one single repsponsibility, to return all files in a directory recursively. It is not the responsibility of BucketManager.cs to do this. Hence we need a new class that has this responsibility.
Another reason to move this method to its own file is that this method is itself 10 lines of code. While you can have methods longer than ten lines, more than ten lines is usually the first sign that the Single Responsibility principal is broken. Most beginning developers have a hard time seeing the many ways a method may be breaking the single responsibility principle. So a much easier rule, is the 10/100 rule. In the 10/100 rule, a method can only have 10 lines. This rule is pretty soft. Do brackets count? It doesn’t matter. What matters is that the 10 line mark, with or without brackets, is where you start looking at refactoring the method by splitting it into two or more smaller and simpler methods. This is a a Keep It Super Simple (K.I.S.S.) rule.
Add the following utility class: FileUtils.cs.
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
namespace Rhyous.AmazonS3BucketManager
{
public static class FileUtils
{
public static async Task&lt;List&lt;string&gt;&gt; GetFiles(string directory, bool recursive)
{
var files = Directory.GetFiles(directory).ToList();
if (!recursive)
return files;
var dirs = Directory.GetDirectories(directory);
var tasks = dirs.Select(d =&gt; GetFiles(d, recursive)).ToList();
while (tasks.Any())
{
var task = await Task.WhenAny(tasks);
files.AddRange(task.Result);
tasks.Remove(task);
}
return files;
}
}
}
Notice: The above class will get all files and directories, recursively. It will do it in parallel. Parallelism likely isn’t needed most of the time. Any non-parallel code that could list files and directories recursively would work. But if you were going to sync directories with tens of thousands of files each, parallelism might be a huge benefit.
Step 2 – Add an UploadFiles method to BucketManager.cs
Edit file called BucketManager.cs.
Enter this new method:
public static async Task UploadFiles(TransferUtility transferUtility, string bucketName, string directory)
{
var files = await FileUtils.GetFiles(directory, true);
var directoryName = Path.GetFileName(directory); // This is not a typo. GetFileName is correct.
var tasks = files.Select(f =&gt; UploadFile(transferUtility, bucketName, f, f.Substring(f.IndexOf(directoryName)).Replace('\\', '/')));
await Task.WhenAll(tasks);
}
Notice 1: We follow the “Don’t Repeat Yourself (DRY) principle by having UploadFiles() forward each file to the singular UploadFile().
Notice 2: We don’t use the await keyword when we redirect each file UploadFile. Instead we capture the returned Task objects and then we will await the completion of each of them.
Step 3 – Update the Action Argument
We should be very good at this by now. We need to make this method a valid action for the Action Argument.
Edit the ArgsHandler.cs file to define an Action argument.
Note: There are enough of these now that I alphabetized them.
Step 4 – Delete the Parameter dictionary
In Part 4, we created a method to pass different parameters to different methods.We took note in Part 8 and Part 9 that we now have more exceptions than we have commonalities. It is time to refactor this.
Another reason to refactor this is because the OnArgumentsHandled method is seriously breaking the 10/100 rule.
Let’s start by deleting what we have.
Delete the Dictionary line from Program.cs.
static Dictionary&lt;string, object[]&gt; CustomParameters = new Dictionary&lt;string, object[]&gt;();
Delete the section where we populated the dictionary.
// Use the Custom or Common pattern
CustomParameters.Add("CreateBucketDirectory", new object[] { s3client, bucketName, Args.Value("Directory") });
CustomParameters.Add("CreateTextFile", new object[] { s3client, bucketName, Args.Value("Filename"), Args.Value("Text") });
CustomParameters.Add("DeleteBucketDirectory", new object[] { s3client, bucketName, Args.Value("Directory") });
CustomParameters.Add("DeleteFile", new object[] { transferUtility, bucketName, Args.Value("Filename") });
CustomParameters.Add("UploadFile", new object[] { transferUtility, bucketName, Args.Value("File"), Args.Value("RemoteDirectory") });
Step 5 – Implement parameters by convention
To refactor the parameter passing, To refactor this, we are going use a convention.
A convention is some arbitrary rule that when followed makes the code work. You have to be very careful when using conventions because they are usually not obvious. Because they are not obvious, the first rule of using a convention is this: Conventions must be documented.
The convention is this: Make the Argument names match the method parameters. Argument names are not case sensitive, so we don’t have to worry about case. Just name.
There are two exceptions to this convention. AmazonsS3Client and TransferUtility. We will handle those exceptions statically in code.
Now, let’s implement our convention.
For each Argument, make sure the associated parameter is the same name.
Change bucketName to bucket in all methods.
Change file to filename in the DeleteFile method.
Change UploadLocation to RemoteDirectory in the UploadFile method.
Change directory to LocalDirectory in the UploadFiles method.
Create the following MethodInfoExtension.cs.
using Amazon;
using Amazon.S3;
using Amazon.S3.Transfer;
using Rhyous.SimpleArgs;
using System;
using System.Collections.Generic;
using System.Configuration;
using System.Reflection;
namespace Rhyous.AmazonS3BucketManager
{
public static class MethodInfoExtensions
{
public static List&lt;object&gt; DynamicallyGenerateParameters(this MethodInfo mi)
{
var parameterInfoArray = mi.GetParameters();
var parameters = new List&lt;object&gt;();
var region = RegionEndpoint.GetBySystemName(ConfigurationManager.AppSettings["AWSRegion"]);
foreach (var paramInfo in parameterInfoArray)
{
if (paramInfo.ParameterType == typeof(AmazonS3Client) || paramInfo.ParameterType == typeof(TransferUtility))
parameters.Add(Activator.CreateInstance(paramInfo.ParameterType, region));
if (paramInfo.ParameterType == typeof(string))
parameters.Add(Args.Value(paramInfo.Name));
}
return parameters;
}
}
}
Notice this class will dynamically query the parameters. AmazonS3Client and TransferUtility are exceptions. The rest of the parameters are created using a convention and pulled from Argument values.
Update Program.cs to use this new extension method.
internal static void OnArgumentsHandled()
{
var action = Args.Value("Action");
var flags = BindingFlags.NonPublic | BindingFlags.Public | BindingFlags.Static | BindingFlags.FlattenHierarchy;
MethodInfo mi = typeof(BucketManager).GetMethod(action, flags);
List&lt;object&gt; parameters = mi.DynamicallyGenerateParameters();
var task = mi.Invoke(null, parameters.ToArray()) as Task;
task.Wait();
}
Notice: Look how simple Program.OnArgumentsHandled method has become. By using this convention, and by moving the parameter creation to an extension method, we are down to six lines. The total size for the Program.cs class is 25 lines, including spaces.
You can now move a directory to an Amazon S3 bucket using C#.
<h3>Design Pattern: Facade</h3>
Yes, we have just implement the popular Facade design pattern.
Our project, and most specifically BucketManger.cs, represent an entire system: Amazon S3. When code is written to represent an entire system or substem, that code is called a Facade.
Additional information: I sometimes cover small sub-topics in a post. Along with AWS, you will also be exposed to:
Rhyous.SimpleArgs
Step 1 – Alter the existing UploadFile method in BucketManager.cs
We need the UploadFile method to take in a parameter that specifies the remote directory, which is the directory path on the S3 bucket. However, if no directory is specified, the key should simply be the file name.
Edit file called BucketManager.cs.
Enter this new method:
Note: We are in luck, the TransferUtility object has an overload that takes in the key.
Additional information: I sometimes cover small sub-topics in a post. Along with AWS, you will also be exposed to:
Rhyous.SimpleArgs
Don’t Repeat Yourself (DRY) Principal
Step 1 – Add a DeleteFile method to BucketManager.cs
Edit file called BucketManager.cs.
Enter this new method:
public static async Task CreateTextFile(AmazonS3Client client, string bucketName, string filename, string text)
{
var dirRequest = new PutObjectRequest
{
BucketName = bucketName,
Key = filename,
InputStream = text.ToStream()
};
await client.PutObjectAsync(dirRequest);
Console.WriteLine($"Created text file in S3 bucket: {bucketName}/{filename}");
}
Notice: The code is almost identical to that of deleting a directory, with only one exception. We aren’t ending with a /. We really should not have duplicate code. So lets fix this in the next step.
Step 2 – Solve the Repetitive Code
It is best practice to avoid having duplicate code. This is often called the “Don’t Repeat Yourself” principal. So let’s update the DeleteBucketDirectory code to forward to the DeleteFile code.
Update the DeleteDirectory method so that both methods share code.
Now the delete directory code is no longer repetitive. A directory is the same as a file, just with a slash. So the Delete directory correctly makes sure that the directory name ends with a slash, then forwards the call to delete file.
Step 3 – Update the Action Argument
We should be very good at this by now. We need to make this method a valid action for the Action Argument.
Edit the ArgsHandler.cs file to define an Action argument.
Note: There are no additional Arguments to add. To delete a file, we need the bucket name and a file name, which we already have Arguments for.
Step 4 – Fix the parameter mismatch problem
In Part 4, we created a method to pass different parameters to different methods. Let’s use that to pass in the correct parameters.
However, take note that we now have more exceptions than we had commonalities. This suggests that it is about time to refactor this code. For now, we will leave it.
// Use the Custom or Common pattern
CustomParameters.Add("UploadFile", new object[] { transferUtility, bucketName, Args.Value("File") });
CustomParameters.Add("CreateBucketDirectory", new object[] { s3client, bucketName, Args.Value("Directory") });
CustomParameters.Add("DeleteBucketDirectory", new object[] { s3client, bucketName, Args.Value("Directory") });
CustomParameters.Add("CreateTextFile", new object[] { s3client, bucketName, Args.Value("Filename"), Args.Value("Text") });
You can now add a text file to an Amazon S3 bucket using C#.
Homework: There is some repetitiveness between CreateFolder and DeleteFolder. What is it? (Hint: Directories end with a slash.)
Additional information: I sometimes cover small sub-topics in a post. Along with AWS, you will also be exposed to:
Rhyous.SimpleArgs
Rhyous.StringLibrary
Step 1 – Add NuGet Package
Right-click on your project and choose Management NuGet Packages.
Search for Rhyous.StringLibrary.
This is a simple library for string extensions methods and more. String code that is not in .Net by default, yet the methods have proven over time to be commonly used.
Install the Rhyous.StringLibrary NuGet package.
Step 2 – Add a CreateTextFile method to BucketManager.cs
Edit file called BucketManager.cs.
Enter this new method:
public static async Task CreateTextFile(AmazonS3Client client, string bucketName, string filename, string text)
{
var dirRequest = new PutObjectRequest
{
BucketName = bucketName,
Key = filename,
InputStream = text.ToStream()
};
await client.PutObjectAsync(dirRequest);
Console.WriteLine($"Created text file in S3 bucket: {bucketName}/{filename}");
}
Notice: The code is almost identical to that of creating a directory, with two exceptions. We aren’t ending with a /. And instead of assigning zero bytes to InputStream, we assigned text.ToStream(). Rhyous.StringLibrary provides us the ToStream() extension method.
Step 2 – Update the Action Argument
We now need to make this method a valid action for the Action Argument.
Edit the ArgsHandler.cs file to define an Action argument.
If we are going to create a text file, we need to know the file name and the text to insert.
Edit the ArgsHandler.cs file to define an Action argument.
...
new Argument
{
Name = "FileName",
ShortName = "N",
Description = "The name of text a file to create.",
Example = "{name}=MyTextfile.txt",
Action = (value) =>
{
Console.WriteLine(value);
}
},
new Argument
{
Name = "Text",
ShortName = "T",
Description = "The text to put in a text file.",
Example = "{name}=\"This is some text!\"",
Action = (value) =>
{
Console.WriteLine(value);
}
}
...
Step 4 – Fix the parameter mismatch problem
In Part 4, we created a method to pass different parameters to different methods. Let’s use that to pass in the correct parameters.
However, take note that we now have more exceptions than we had commonalities. This suggests that it is about time to refactor this code. For now, we will leave it.
// Use the Custom or Common pattern
CustomParameters.Add("UploadFile", new object[] { transferUtility, bucketName, Args.Value("File") });
CustomParameters.Add("CreateBucketDirectory", new object[] { s3client, bucketName, Args.Value("Directory") });
CustomParameters.Add("DeleteBucketDirectory", new object[] { s3client, bucketName, Args.Value("Directory") });
CustomParameters.Add("CreateTextFile", new object[] { s3client, bucketName, Args.Value("Filename"), Args.Value("Text") });
You can now add a text file to an Amazon S3 bucket using C#.
In Part 4, we created a method to pass different parameters to different methods. Let’s use that to pass in the correct parameters.
// Use the Custom or Common pattern
CustomParameters.Add("UploadFile", new object[] { transferUtility, bucketName, Args.Value("File") });
CustomParameters.Add("CreateBucketDirectory", new object[] { s3client, bucketName, Args.Value("Directory") });
CustomParameters.Add("DeleteBucketDirectory", new object[] { s3client, bucketName, Args.Value("Directory") });
Additional information: I sometimes cover small sub-topics in a post. Along with AWS, you will also be exposed to:
Rhyous.SimpleArgs
Don’t Repeat Yourself (DRY) Principal
Step 1 – Add a DeleteFile method to BucketManager.cs
Edit file called BucketManager.cs.
Enter this new method:
public static async Task CreateTextFile(AmazonS3Client client, string bucketName, string filename, string text)
{
var dirRequest = new PutObjectRequest
{
BucketName = bucketName,
Key = filename,
InputStream = text.ToStream()
};
await client.PutObjectAsync(dirRequest);
Console.WriteLine($"Created text file in S3 bucket: {bucketName}/{filename}");
}
Notice: The code is almost identical to that of deleting a directory, with only one exception. We aren’t ending with a /. We really should not have duplicate code. So lets fix this in the next step.
Step 2 – Solve the Repetitive Code
It is best practice to avoid having duplicate code. This is often called the “Don’t Repeat Yourself” principal. So let’s update the DeleteBucketDirectory code to forward to the DeleteFile code.
Update the DeleteDirectory method so that both methods share code.
Now the delete directory code is no longer repetitive. A directory is the same as a file, just with a slash. So the Delete directory correctly makes sure that the directory name ends with a slash, then forwards the call to delete file.
Step 3 – Update the Action Argument
We should be very good at this by now. We need to make this method a valid action for the Action Argument.
Edit the ArgsHandler.cs file to define an Action argument.
If we are going to create a text file, we need to know the file name and the text to insert.
Edit the ArgsHandler.cs file to define an Action argument.
...
new Argument
{
Name = "FileName",
ShortName = "N",
Description = "The name of text a file to create.",
Example = "{name}=MyTextfile.txt",
Action = (value) =>
{
Console.WriteLine(value);
}
},
new Argument
{
Name = "Text",
ShortName = "T",
Description = "The text to put in a text file.",
Example = "{name}=\"This is some text!\"",
Action = (value) =>
{
Console.WriteLine(value);
}
}
...
Step 4 – Fix the parameter mismatch problem
In Part 4, we created a method to pass different parameters to different methods. Let’s use that to pass in the correct parameters.
However, take note that we now have more exceptions than we had commonalities. This suggests that it is about time to refactor this code. For now, we will leave it.
// Use the Custom or Common pattern
CustomParameters.Add("UploadFile", new object[] { transferUtility, bucketName, Args.Value("File") });
CustomParameters.Add("CreateBucketDirectory", new object[] { s3client, bucketName, Args.Value("Directory") });
CustomParameters.Add("DeleteBucketDirectory", new object[] { s3client, bucketName, Args.Value("Directory") });
CustomParameters.Add("CreateTextFile", new object[] { s3client, bucketName, Args.Value("Filename"), Args.Value("Text") });
You can now add a text file to an Amazon S3 bucket using C#.
Homework: There is some repetitiveness between CreateFolder and DeleteFolder. What is it? (Hint: Directories end with a slash.)
In Part 4, we created a method to pass different parameters to different methods. Let’s use that to pass in the correct parameters.
// Use the Custom or Common pattern
CustomParameters.Add("UploadFile", new object[] { transferUtility, bucketName, Args.Value("File") });
CustomParameters.Add("CreateBucketDirectory", new object[] { s3client, bucketName, Args.Value("Directory") });
Notice 1: This method has different parameters. We are going to have to fix Program.cs later. Up until now, all of our methods had the same parameters.
Notice 2: The content of this method is an action we would like to run asynchronously, but it is not asynchronous. Task.Run is a static method that runs any method you call inside it asynchronously.
Step 2 – Update the Action Argument
We now need to make this method a valid action for the Action Argument.
Edit the ArgsHandler.cs file to define an Action argument.
If we are going to upload a file, we should know which file it is.
new Argument
{
Name = "File",
ShortName = "f",
Description = "The file.",
Example = "{name}=c:\\some\file.txt",
CustomValidation = (value) =>
{
return File.Exists(value);
},
Action = (value) =>
{
Console.WriteLine(value);
}
}
Notice: One of the cool features of SimpleArgs is the ability to declare custom validation. We don’t have to check elsewhere in our code if the file exists. We can use that to validate whether the File parameter is valid or not.
Step 4 – Fix the parameter mismatch problem
To be nice and S.O.L.I.D., our program now needs to determine the method’s dependencies and inject them into the method. It needs to do this dynamically at runtime.
Well, with only one exception, it is most easy to use the Custom or Common pattern. The Custom or Common pattern simply means checking for a customization and if no customization exists, use the common implementation.
To implement this, we could just use a simple IF condition. But just to demonstrate how a Dictionary can be used for the Custom or Common pattern, I will use it.
class Program
{
static void Main(string[] args)
{
new ArgsManager<ArgsHandler>().Start(args);
}
static Dictionary<string, object[]> CustomParameters = new Dictionary<string, object[]>();
internal static void OnArgumentsHandled()
{
var action = Args.Value("Action");
var bucketName = Args.Value("Bucket");
var file = Args.Value("File");
var flags = BindingFlags.NonPublic | BindingFlags.Public | BindingFlags.Static | BindingFlags.FlattenHierarchy;
MethodInfo mi = typeof(BucketManager).GetMethod(action, flags);
var region = RegionEndpoint.GetBySystemName(ConfigurationManager.AppSettings["AWSRegion"]);
var s3client = new AmazonS3Client(region);
var transferUtility = new TransferUtility(region);
// Use the Custom or Common pattern
CustomParameters.Add("UploadFile", new object[] { transferUtility, bucketName, file });
object[] parameters;
if (!CustomParameters.TryGetValue(action, out parameters))
parameters = new object[] { s3client, bucketName };
var task = mi.Invoke(null, parameters) as Task;
task.Wait();
}
}
Notice in line 8 we create a dictionary. In line 24 we populate the dictionary with a customization. In Lines 26 and 27, we try to get a custom parameter array and if we don’t find it, we use the default one.
Homework: What if every method had different parameters? What would you do?
Additional information: I sometimes cover small sub-topics in a post. Along with AWS, you will also be exposed to:
async, await, Task
Rhyous.SimpleArgs
Step 1 – Add a ListFiles method to BucketManager.cs
Edit file called BucketManager.cs.
Enter this new method:
public static async Task ListFiles(AmazonS3Client client, string bucketName)
{
var listResponse = await client.ListObjectsV2Async(new ListObjectsV2Request { BucketName = bucketName });
if (listResponse.S3Objects.Count > 0)
{
Console.WriteLine($"Listing items in S3 bucket: {bucketName}");
listResponse.S3Objects.ForEach(o => Console.WriteLine(o.Key));
}
}
Note: I noticed there was a ListObjectsAsync and a ListObjectsV2Async. I assumed the one with V2 is newer and should be used for new code. The documentation for ListObjectsV2Async confirmed this.
Step 2 – Update the Action Argument
We now need to make this method a valid action for the Action Argument.
Edit the ArgsHandler.cs file to define an Action argument.
Notice: We didn’t have a step 3. We wrote some S.O.L.I.D. code in Part 1 and Part 2, which made it really easy for us to implement this method.
Homework: I also read in the documentation that only 1000 files will be listed when a call to ListObjectsV2Async is made. What if you have more than 1000 files, how would you list them all?
Additional information: I sometimes cover small sub-topics in a post. Along with AWS, you will also be exposed to:
async, await, Task
Reflection
Rhyous.SimpleArgs
Single Responsibility Principal (S of S.O.L.I.D.) or Don’t Repeat Yourself (DRY)
Dependency Injection – Method Injection (D of S.O.L.I.D.)
Step 1 – Add a DeleteBucket method to BucketManager.cs
Edit file called BucketManager.cs.
Enter this new method:
public static async Task DeleteBucket(string bucketName)
{
var region = RegionEndpoint.GetBySystemName(ConfigurationManager.AppSettings["AWSRegion"]);
var client = new AmazonS3Client(region);
await AmazonS3Util.DeleteS3BucketWithObjectsAsync(client, bucketName);
Console.WriteLine($"Deleted S3 bucket: {bucketName}");
}
Notice that there is more involved with deleting a bucket than creating a bucket. A bucket may not be empty. It could have files in it already. Because of this we call a helper method, DeleteS3BucketWithObjectsAsync, that deletes a bucket even if it has objects, i.e. files, in it.
Step 2 – Configure an Argument for the Action to call
Since BucketManager can now can both Create and Delete a bucket, we need an argument to specify what action we would like to call.
Edit the ArgsHandler.cs file to define an Action argument.
SimpleArgs allows for arguments to be declarative and provides most the features you would want in command line arguments without having to write those features for every new application.
new Argument
{
Name = "Action",
ShortName = "a",
Description = "The action to run.",
Example = "{name}=default",
DefaultValue = "Default",
AllowedValues = new ObservableCollection<string>
{
"CreateBucket",
"DeleteBucket"
},
IsRequired = true,
Action = (value) =>
{
Console.WriteLine(value);
}
}
Notice: We don’t have to validate that the correct method was passed in as a variable because SimpleArgs will do this for us by simply declaring them as AllowedValues. When AllowedValues is declared, only those values are allowed. Any other value will result in the application stopping and outputting the list of valid arguments.
Step 3 – Edit the Program.cs
We are now going to use reflection to call the appropriate function based on our action parameter.
Edit the OnArgumentsHandled method of Program.cs.
internal static void OnArgumentsHandled()
{
var action = Args.Value("Action");
var bucketName = Args.Value("Bucket");
var flags = BindingFlags.NonPublic | BindingFlags.Public | BindingFlags.Static | BindingFlags.FlattenHierarchy;
MethodInfo mi = typeof(BucketManager).GetMethod(action, flags);
var task = mi.Invoke(null, new[] { bucketName }) as Task;
task.Wait();
}
Step 4 – Make the code S.O.L.I.D.
We have broken the Single Responsibility Principal (S in S.O.L.I.D.) or Don’t Repeat Yourself (DRY) rule. Let’s notice it and fix it.
Notice in BucketManager.cs that both methods are breaking two rules:
Don’t Repeat Yourself or DRY: We have two methods repeating the same two lines of code.
var region = RegionEndpoint.GetBySystemName(ConfigurationManager.AppSettings["AWSRegion"]);
var client = new AmazonS3Client(region);
Single Responsibility Principal: Each method has one repsponsibility. CreateBucket should only create a bucket on the Amazon S3 server. DeletBucket should only delete a bucket. Currently, both methods are having to instantiate a client and figure out the region. That isn’t the responsibility of these methods.
Let’s solve this with Method Injection. Method Injection is a form of Dependency Injection (D in S.O.L.I.D.). We will pass the client into the method.
Note: I am using method injection because all the methods are static, so Constructor Injection is not an option. Property Injection is an option. A Lazy-injectable Property would also be a very good option here.
Alter the methods to take in an AmazonS3Client object.
using Amazon.S3;
using Amazon.S3.Util;
using System;
using System.Threading.Tasks;
namespace Rhyous.AmazonS3BucketManager
{
public class BucketManager
{
public static async Task CreateBucket(AmazonS3Client client, string bucketName)
{
await client.PutBucketAsync(bucketName);
Console.WriteLine($"Created S3 bucket: {bucketName}");
}
public static async Task DeleteBucket(AmazonS3Client client, string bucketName)
{
await AmazonS3Util.DeleteS3BucketWithObjectsAsync(client, bucketName);
Console.WriteLine($"Deleted S3 bucket: {bucketName}");
}
}
}
Update the Program.cs to instantiate the client and pass it into the methods.
internal static void OnArgumentsHandled()
{
var action = Args.Value("Action");
var bucketName = Args.Value("Bucket");
var flags = BindingFlags.NonPublic | BindingFlags.Public | BindingFlags.Static | BindingFlags.FlattenHierarchy;
MethodInfo mi = typeof(BucketManager).GetMethod(action, flags);
var region = RegionEndpoint.GetBySystemName(ConfigurationManager.AppSettings["AWSRegion"]);
var client = new AmazonS3Client(region);
var task = mi.Invoke(null, new object[] { client, bucketName }) as Task;
task.Wait();
}
Notice we now only create a client one time.
Note: The OnArgumentsHandled in our Program.cs is now doing four things. As you can see above, it has each thing it does in a pair of lines, with each pair of lines separated by a double space. This is where we want to be careful to not overdo it when following design patterns. We only have eight lines of code. Program.cs is supposed to be a program. It is fine for now. Let’s not change it. Notice it. Consider changing it. This time we decided to leave it, but we can keep it in mind. If more lines are added, then that method probably should be changed.
You are familiar with creating projects in Visual Studio.
We assume you have already gone to AWS and registered with them. If you haven’t done that already, stop and go there now. Amazon has a free tier and you can create an account here: https://aws.amazon.com/free
Additional Information: I sometimes cover small sub-topics in a post. Along with AWS, you will also be exposed to:
.NET Core 2.0 – If you use .NET Framework, the steps will be slightly different, but as this is a beginner level tutorial, it should be simple.
async, await, Task
Rhyous.SimpleArgs
Step 1 – Create the project
Open Visual Studio.
Go to File | New Project.
Choose Console Application.
Give it any name you want.
I am going to call my project Rhyous.AmazonS3BucketManager.
Step 2 – Add NuGet Packages
Right-click on your project and choose Management NuGet Packages.
Search for AWSSDK.S3.
Install the NuGet package and all the dependencies.
Search for System.Configuration.ConfigurationManager.
Install it.
Step 3 – Create a BucketManager.cs file
Create a new file called BucketManager.cs.
Enter this code:
using Amazon;
using Amazon.S3;
using System;
using System.Configuration;
using System.Threading.Tasks;
namespace Rhyous.AmazonS3BucketManager
{
public class BucketManager
{
public static async Task CreateBucket(string bucketName)
{
var region = RegionEndpoint.GetBySystemName(ConfigurationManager.AppSettings["AWSRegion"]);
var client = new AmazonS3Client(region);
await client.PutBucketAsync(bucketName);
Console.WriteLine($"Created S3 bucket: {bucketName}");
}
}
}
Step 4 – Edit the Program.cs
Add the following to Program.cs.
static void Main()
{
var task = BucketManager.CreateBucket("my.new.bucket");
task.Wait();
}
Step 5 – Create/Edit the App.config
If there isn’t an app.config in your project, create one.
Right-click on your project and choose Add | New Item.
Search for Application Configuration File.
Make sure it is name app.config.
Add an appSetting for your AWS profile name.
Add an additional appSetting for your chosen AWS region.
Step 6 – Configure an Argument for the bucket name.
We are going to be adding to this program in subsequent posts. For this reason, we are going to use Rhyous.SimpleArgs library for our command line arguments as it provides ready-made command line argument features.
Install another NuGet Package.
Right-click on your project and choose Management NuGet Packages.
Search for Rhyous.SimpleArgs
Install it.
Create an ArgsHandler.cs file to define the arguments:
Note: If you used a .NET core project you have to create this file. If you created a .NET Framework file, this file should have been created for you and you have but to edit it.
using Rhyous.SimpleArgs;
using System;
using System.Collections.Generic;
using System.Text.RegularExpressions;
namespace Rhyous.AmazonS3BucketManager
{
public class ArgsHandler : ArgsHandlerBase
{
public override void InitializeArguments(IArgsManager argsManager)
{
Arguments.AddRange(new List<Argument>
{
new Argument
{
Name = "Bucket",
ShortName = "b",
Description = "The bucket name to create. No uppercase or underscores allowed.",
Example = "{name}=my.first.bucket",
DefaultValue = "my.first.bucket",
IsRequired = true,
CustomValidation = (value) =>
{
return Regex.IsMatch(value, "^[a-z0-9.]+$");
},
Action = (value) =>
{
Console.WriteLine(value);
}
}
});
}
public override void HandleArgs(IReadArgs inArgsHandler)
{
base.HandleArgs(inArgsHandler);
Program.OnArgumentsHandled();
}
}
}
Update Program.cs as follows:
using Rhyous.SimpleArgs;
using System;
namespace Rhyous.AmazonS3BucketManager
{
class Program
{
static void Main(string[] args)
{
new ArgsManager<ArgsHandler>().Start(args);
}
internal static void OnArgumentsHandled()
{
var bucketName = Args.Value("Bucket");
var task = BucketManager.CreateBucket(bucketName);
task.Wait();
}
}
}
Now for fun, you can delete the app.config and change them to parameters.